
前言
oo第一单元的任务是表达式括号展开与化简,课程组的目的在于通过这一十分结构化的任务来把我们引入面向对象的设计思想,并设计了三次迭代作业开发,旨在模拟真实的作业环境。
这一个月以来,确实在oo这门课上吃了不少苦,但通过自己的努力从第一次作业进C组到第三次作业强测无bug,互测只有一个bug,也学到了一些东西。通过这篇博客,本人将对自己的这三次代码进行详细分析,并做一些总结。
第一次作业
第一次作业是对单变量(x)的多项式的展开。
UML类图与架构设计
本次作业代码的UML图如下
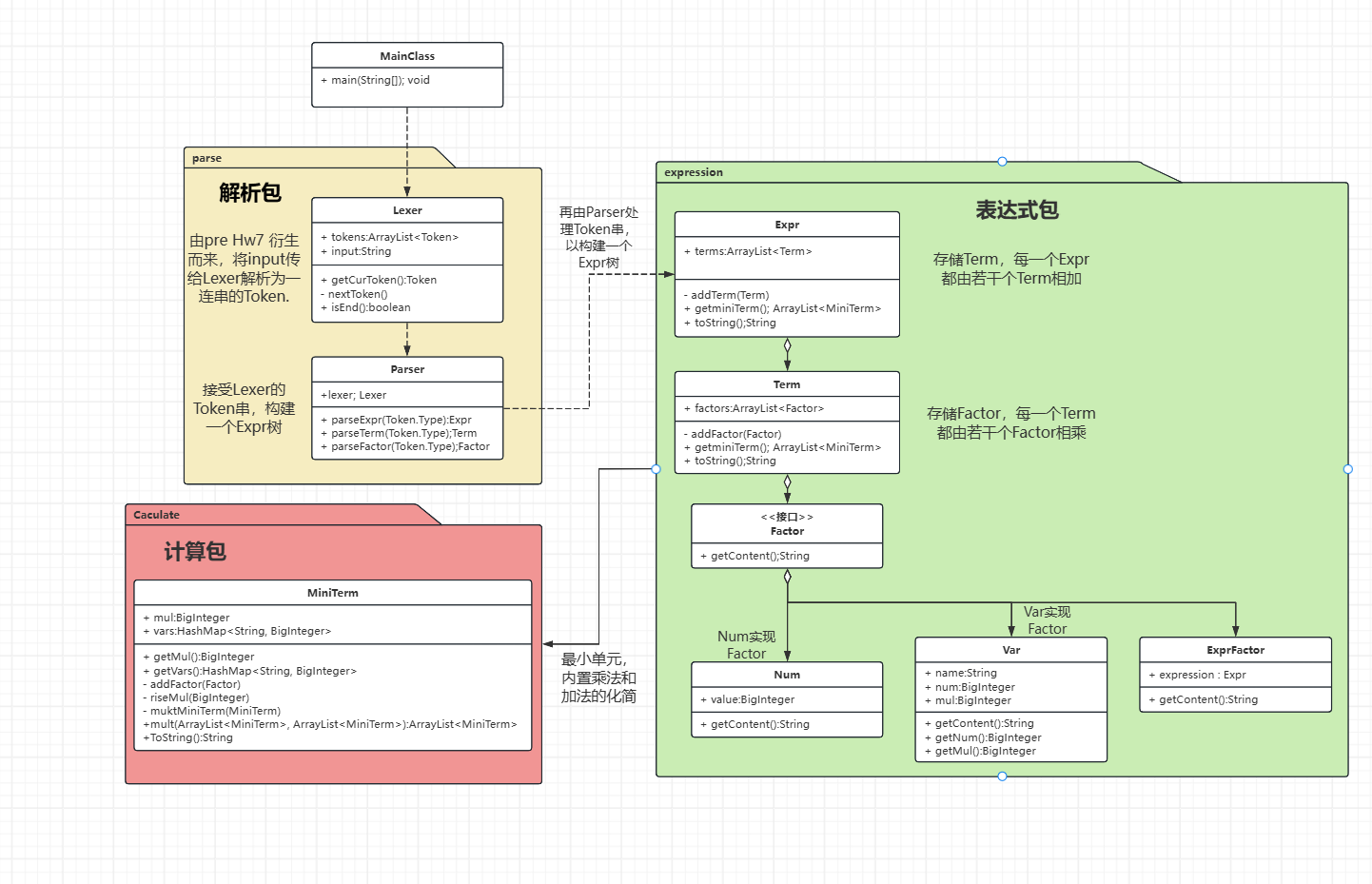
任务分析
表达式解析
这部分内容比较简单,我们沿用pre中hw7递归下降的做法,首先将Input传给Lexer,在Lexer建立的过程中,就完成了对各种符号的特异提取以及对变量(这里只有x)和数字的识别,并存储为一个Token串。然后将建立好的Lexer传递给parser。
我们第一次听说递归下降的时候可能会感到有些陌生。递归下降,在这里就是通过层层递归调用来完成对字符串Input的结构化建树,代码逻辑和建树的过程一致,自顶向下的建立好每一个分支。
我们这里需要建立的就是一个Expression的树,根节点是一个Expr,它由若干个子节点Term相加表述而成。同理,Term由若干个Factor相乘表述而成,若Factor是Num或者Var则递归到了终点,若为ExprFactor(一种特殊的Factor,内容是一个Expr)则跳到对Expr的解析。
所以代码中递归下降的核心就在于parser的parseExpr()中。
调用这个函数后会返回一个建立好的Expr,并交给下一步处理。
括号展开
这部分是本次作业的难点,我们需要将表达式展开为如下形式:
$$ E = \sum ax^i $$
我们不难发现,这种形式的最小单元是一个单项式,于是我们建立MiniTerm类来描述这个最小单元(事实上一开始的实现并不好,代码结构混乱,也导致了很多的bug,我将在后面重构整个代码结构,但是大致的思路没什么问题)。
我们在类内部实现MiniTerm的乘法和加法的化简,来实现对括号的展开,由于会重构的原因,代码展示会放在后面的部分。
代码设计
表达式解析
本部分沿用了pre的代码,这里就不再展开了。
括号展开
重构前
其实可以发现在重构前,可以发现我的代码有两个主要的问题:
- Expr、Term和Factor内部的属性其实并不是真正的private的,存在大量的get方法将他们暴露在外,也导致了我的不良的代码结构和很多的bug。
- 建类混乱,没有清晰的层次结构。
如,我对于展开后的表达式的结构化没有表示的很好,只有一个简单的最小单元类,事实上应该有一个多项式类来管理多项式乘法,将其与单项式加法区分开。
重构后
首先是我重构后的UNL类图:
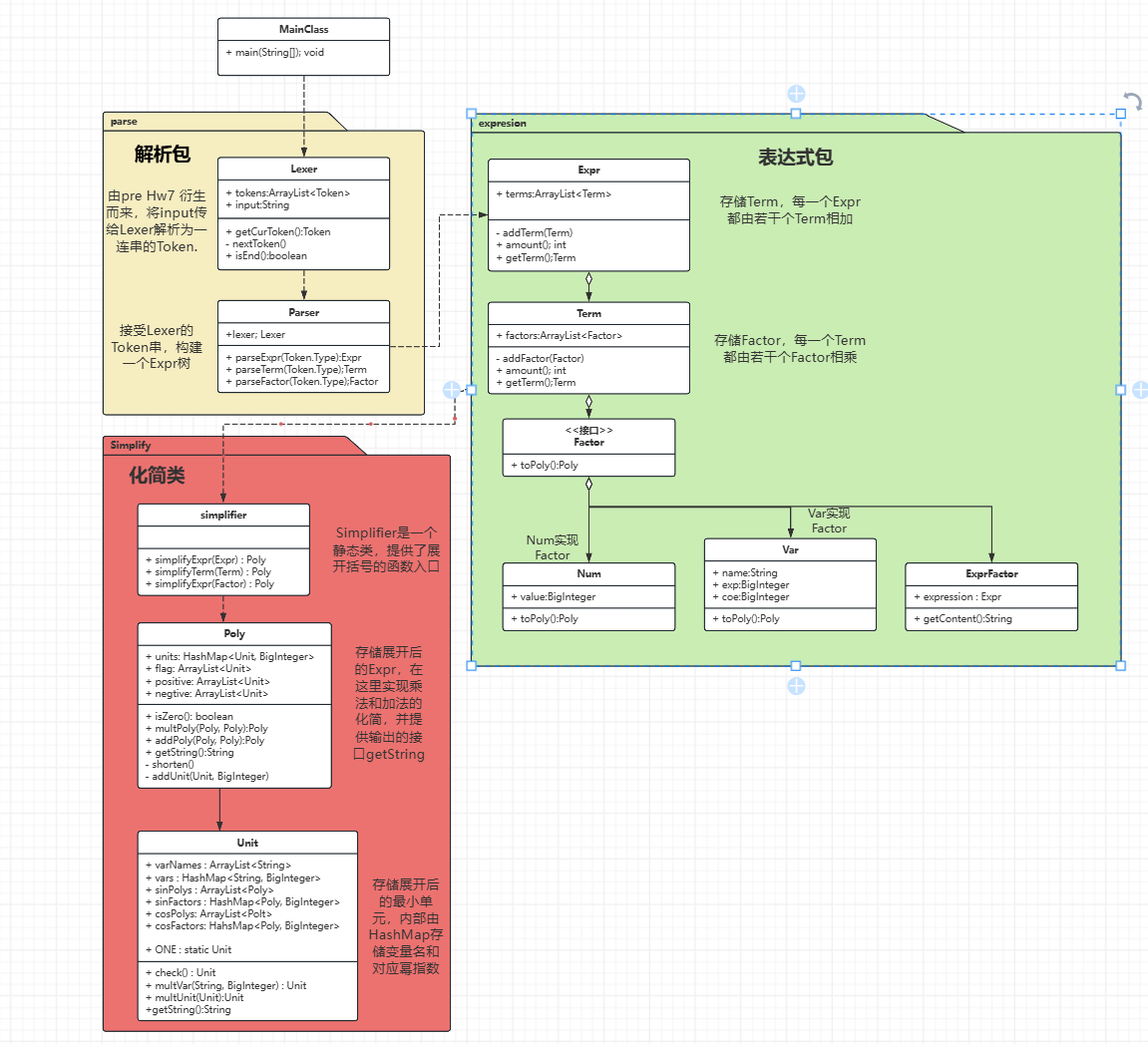
可以发现,我对于解析包做了保留,主要在化简包上做了工作。
首先,我建立了一个静态的类Simplifier,它内部的函数simplifyExpr(Expr expr)会将传进来的expr按层次解析:
public static Poly simplifyExpr(Expr expresiton) {
Poly result = new Poly();
for (int i = 0; i < expresiton.amount(); i = i + 1) {
Term term = expresiton.getTerm(i);
Poly termPoly = simplifyTerm(term);
result = Poly.addPoly(result, termPoly);
}
return result;
}
public static Poly simplifyTerm(Term term) {
Poly result = new Poly();
for (int i = 0; i < term.amount(); i = i + 1) {
Factor factor = term.getFactor(i);
Poly factorPoly = simplifyFactor(factor);
result = Poly.multPoly(result, factorPoly);
}
return result;
}
public static Poly simplifyFactor(Factor factor) {
return factor.toPoly();
}
把解析的过程完全脱离于其他工作,代码结构清晰了不少。
我们可以发现在simplifyFactor(Factor factor)调用了toPoly()方法,这就要引入我们的Poly类了。
主要属性如下:
private HashMap<Unit, BigInteger> units;
private ArrayList<Unit> flag;
其中units用来储存这次作业的最小单元:单项式和对于的幂;flag用来储存units中的Key,主要作用是在后期取值时保护属性不暴露在外,也方便索引unit。
然后我们在Poly中实现了对Unit的加法:
public void addUnit(Unit m, BigInteger c) {
Unit newM = m.check();
if (units.containsKey(newM)) {
BigInteger coe = units.get(newM);
coe = coe.add(c);
if (coe.equals(BigInteger.ZERO)) {
units.remove(newM);
flag.remove(newM);
if (!units.containsKey(Unit.ONE)) {
units.put(Unit.ONE, BigInteger.ZERO);//保留常数项
flag.add(Unit.ONE);
}
}
units.replace(newM, coe);
} else {
units.put(newM, c);
flag.add(newM);
}
}
还实现了对Poly的乘法和加法:
public static Poly multPoly(Poly poly1, Poly poly2) {
if (poly1.amount() == 0) {
return poly2;
}
if (poly2.amount() == 0) {
return poly1;
}
Poly result = new Poly();
for (Unit unit1 : poly1.units.keySet()) {
for (Unit unit2 : poly2.units.keySet()) {
//...
}
}
return result;
}
public static Poly addPoly(Poly poly1, Poly poly2) {
Poly result = new Poly();
for (Unit unit : poly1.units.keySet()) {
result.addUnit(unit, poly1.units.get(unit));
}
for (Unit unit : poly2.units.keySet()) {
result.addUnit(unit, poly2.units.get(unit));
}
return result;
}
在以上的运算中始终保持最终的返回结果是最简的。
这样之后,我们就可以在Factor中每一个类都写一个toPoly方法,并层层向上传递,当传到顶层的时候就构建好了我们所需要的没有括号的表达式结构了。
这次重构给我带来的感受很多,主要有以下几点:
- 不要为了优化代码量和代码性能而丧失代码的结构性和可读性。
- 对于一个类的内容的处理要在对应的类中写一个方法来实现,并返回最终的结果。这样既减少了代码的耦合性,又增加了代码的可读性。
第二次作业
UML类图与架构设计
如下:
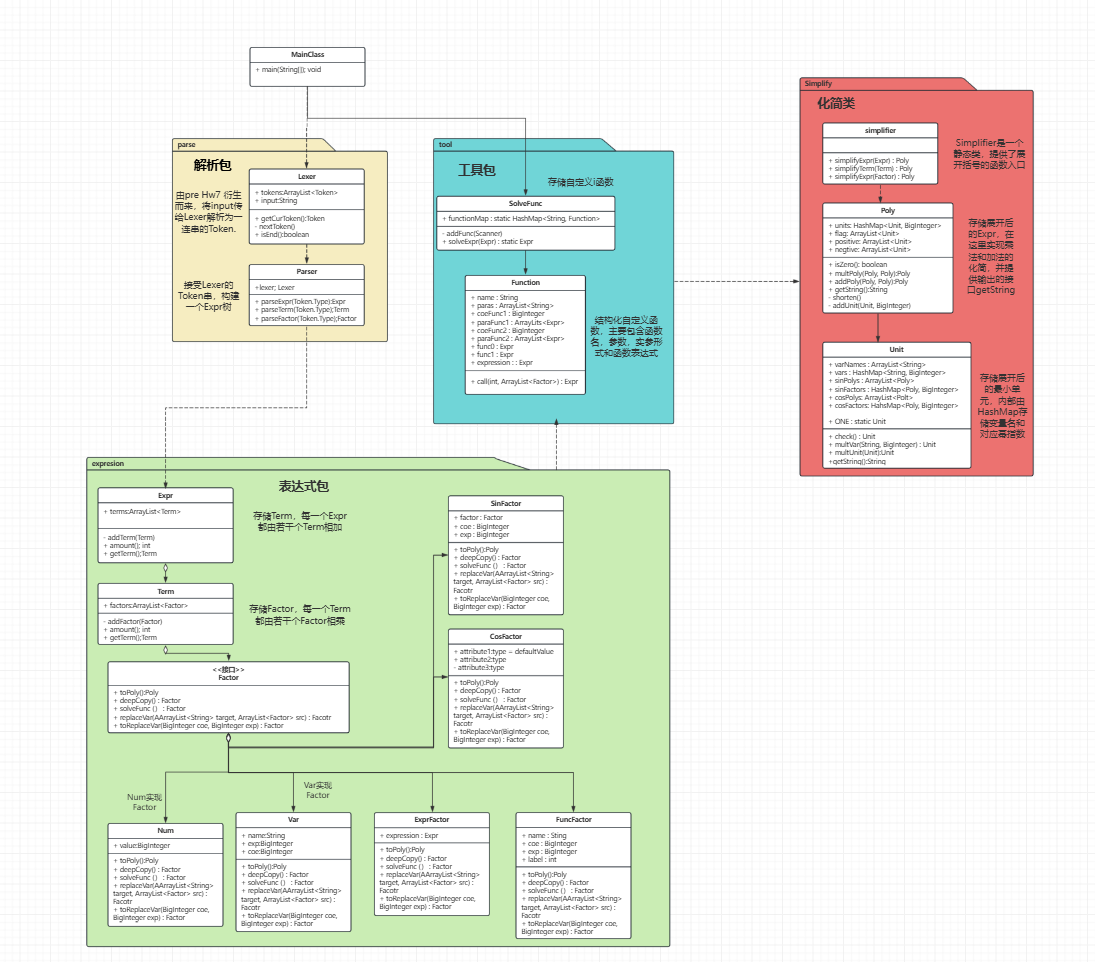
代码架构分析
第二次作业新增的内容是括号嵌套、递归自定义函数和三角函数因子。
由于我在上一次作业已经实现了括号嵌套(ExprFactor递归到Expr)所以这次作业我将就三角函数因子和自定义递归函数的处理讲解。
三角函数因子
这部分内容比较简单,我们首先需要在Factor接口新增两个实现即可,分别是SinFactor和CosFactor,并实现其toPoly()方法。
其次需要改写Unit,新增如下属性
private ArrayList<Poly> sinPolys;
private HashMap<Poly, BigInteger> sinFactors;
private ArrayList<Poly> cosPolys;
private HashMap<Poly, BigInteger> cosFactors;
并改写Poly和Unit的乘法加法逻辑即可,就可以完成三角函数因子这部分内容。
要注意的是三角函数因子内部存储的内容是因子。
递归自定义函数
说实话,这部分内容花了我很大一部分心思,我初期苦恼于如何有效的存储自定义函数和调用自定义函数。
经过一天的思考后我的解决方案是沿用递归下降的思路遍历Expr树:
1.新建一个Function类,类内部的属性为:
private final String name;//函数名
private final ArrayList<String> paras;//形参列表
private final BigInteger coeFunc1;//n-1项的系数
private final ArrayList<Expr> paraFunc1; //n-1项的实参形式,用Expr储存
private final BigInteger coeFunc2;//n-2项的系数
private final ArrayList<Expr> paraFunc2; //n-2项的实参形式,用Expr储存
private final Expr func0;//0项的形参表达式
private final Expr func1;//1项的形参表达式
private final Expr expression;//函数表达式
2.新建一个静态SolveFunc类存储已经定义好的函数,用函数名索引Function存在HashMap中,处理传入的Expr,替换所有的FuncFactor后返回新的Expr。内部方法如下:
public static Expr solveExpr(Expr expr) {
Expr newExpr = new Expr();
for (int i = 0; i < expr.amount(); i += 1) {
Term term = expr.getTerm(i);
term = solveTerm(term);
newExpr.addTerm(term);
}
return newExpr;
}
public static Term solveTerm(Term term) {
Term newTerm = new Term();
for (int i = 0; i < term.amount(); i += 1) {
Factor factor = term.getFactor(i);
newTerm.addFactor(solveFactor(factor));
}
return newTerm;
}
public static Factor solveFactor(Factor factor) {
return factor.solveFunc();
}
3.在所有Factor中实现对FuncFactor的处理,以实现替换书上的所有FuncFactor节点。
具体逻辑是遍历树上的每一个Factor节点,若遇上FuncFactor则调用Function.call()并传入该函数因子的信息,替换的逻辑中也沿用了递归下降的想法,先自顶向下构建好待替换的Expr(设计斐波那契递归,层层计算n-1项Expr和n-2项Expr然后相加返回到上一层),然后包装成ExprFactor后放入FuncFactor的位置即可。
经过上述操作后,Expr没有了FuncFactor节点,传给Simplifier进行括号展开即可。
Poly和Unit的新增内容
本次作业的最小单元不再是 $ax^n$ 而是 $ ax^n\prod_{i}sin(Factor_i)\prod_{i}cos(Factor_i)$
所以我们只需要改写一下加法和乘法的逻辑保证依然在计算的过程中是最简的即可。
第三次作业
UML类图与架构设计
如下:
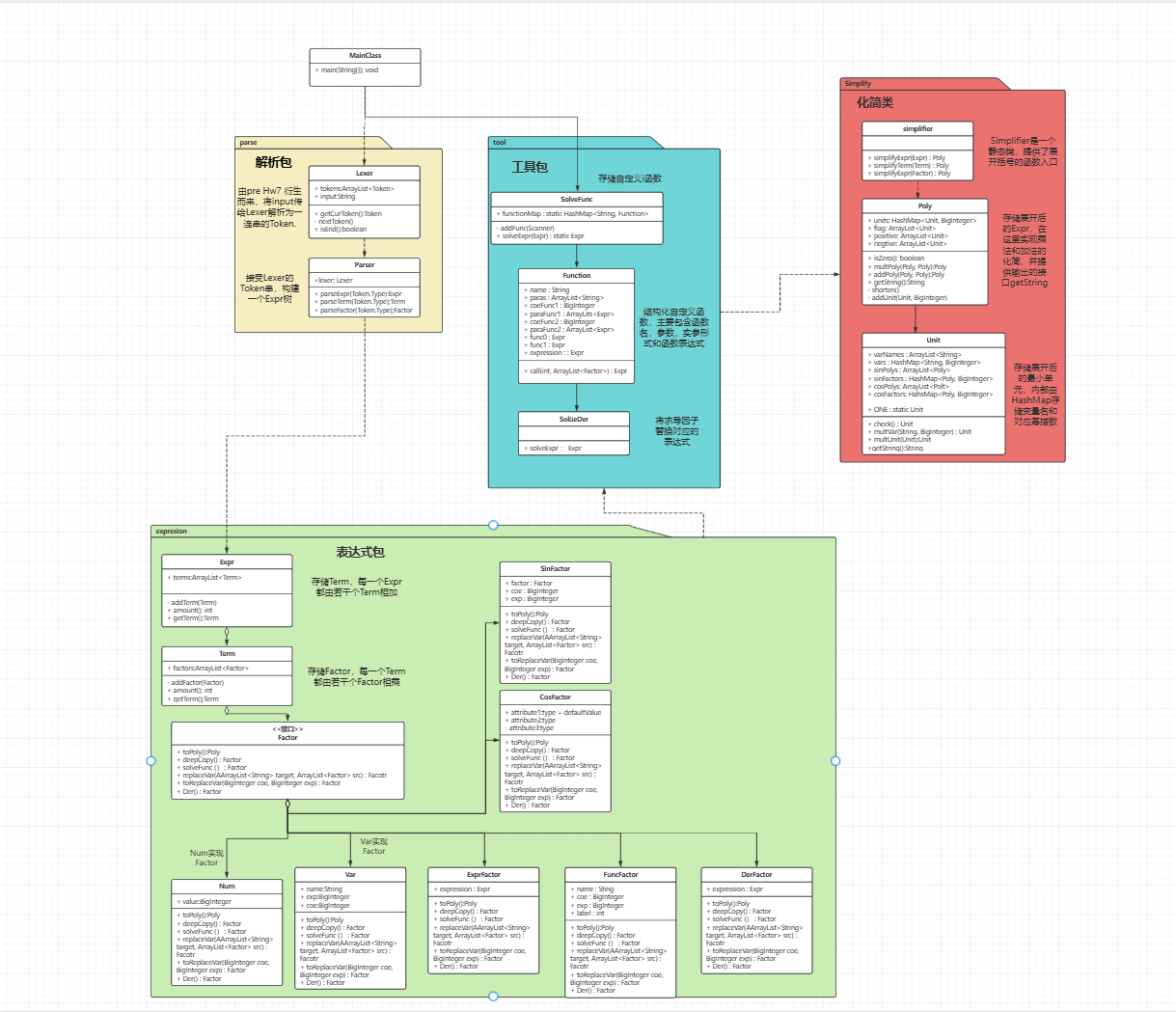
代码架构分析
可以发现,第三次作业的UML类图相比较于第二次作业的UML类图几乎没什么改动,一方面是因为这次作业的新增内容只有求导因子和自定义普通函数,另一方面是因为在第一次重构后我的代码的架构的优良。
由此也是第一次尝到了架构好的甜处。
自定义普通函数
由于上一次作业已经实现了自定义递归函数,那我们也可以把自定义普通函数归于此,只需要把它看作递归深度为0的自定义递归函数即可,call时直接返回储存的0项表达式。
求导因子
第一步和第二次作业一样,先增加求导因子实现Factor这个接口。我们不难发现,实现求导的过程其实和替换FuncFactor的过程是可以很相似的,我们只需要一样的遍历整个树,当发现求导因子时,就递归的构建起表达式即可,这部分实现,我们放在了DerFactor里,代码结构如下:
//SolveDer内容
public static Expr solveExpr(Expr expr) {
Expr newExpr = new Expr();
for (int i = 0; i < expr.amount(); i += 1) {
Term term = expr.getTerm(i);
term = solveTerm(term);
newExpr.addTerm(term);
}
return newExpr;
}
public static Term solveTerm(Term term) {
Term newTerm = new Term();
for (int i = 0; i < term.amount(); i += 1) {
Factor factor = term.getFactor(i);
newTerm.addFactor(solveFactor(factor));
}
return newTerm;
}
public static Factor solveFactor(Factor factor) {
return factor.solveDer();
}
//DerFactor内容
@Override
public Factor solveDer() {
Expr newExpr = SolveDer.solveExpr(expr);//先解决expr的dx
newExpr = (Expr) newExpr.derive(); // expr.derive返回的是表达式
return new ExprFactor(newExpr, coe, exp);
}
然后这次作业就很简单的被我们完成了。(好耶!!
Bug分析
很不幸,本人在Unit1出现了许多的bug,让我们来一一分析一下bug的原因。
HW1
在上文我们已经说过,第一作业的bug大多因为架构的不合理和代码风格的差劲。
那么不合理之处在哪呢?
1.类之间的耦合度高,没有做到把任务分解简化,而是让同一块处理多个混合的任务,非常容易导致bug。
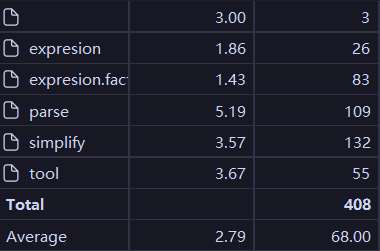
下面就是hw1改写前的一些代码指标:
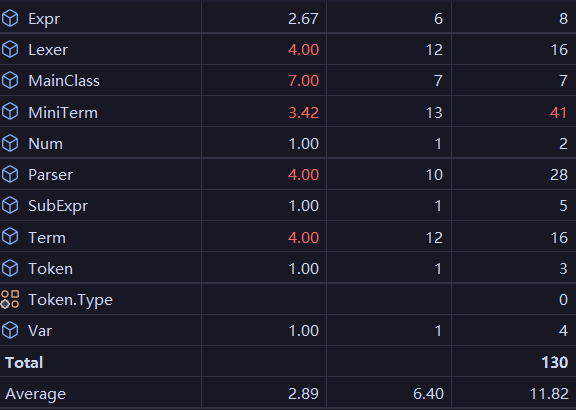
从左至右分别为OCavg Ocmax WMC
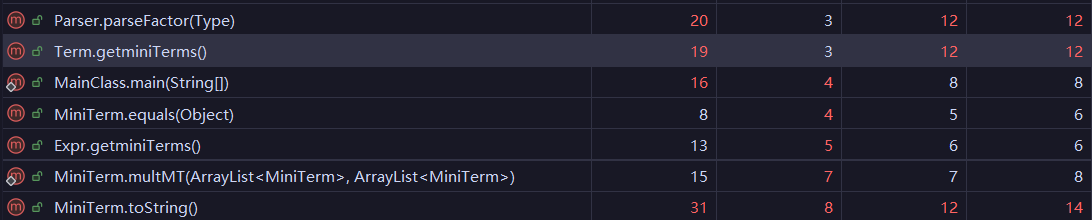
从左至右分别为Cogc ec(G) iv(G) v(G)
我们可以很明显的看出计算类和主类在多个指标中出现了不合理的数值,这明显是有缺陷的。
而在重构之后:
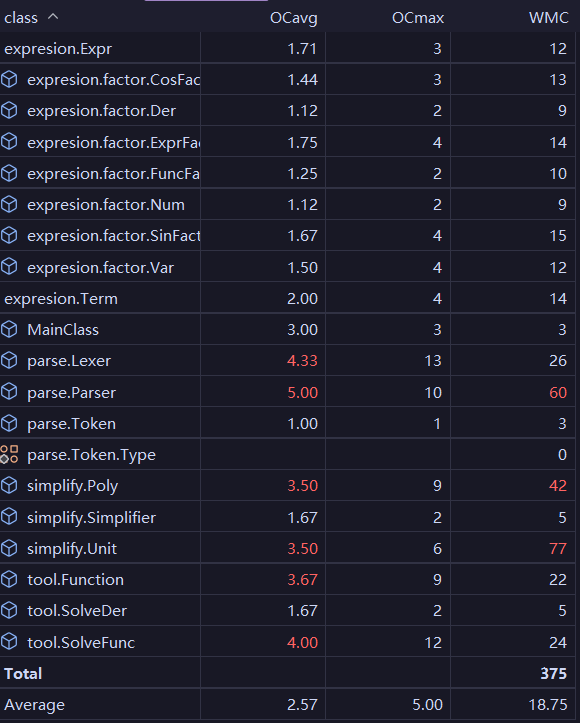
计算类的指标好了许多,直观上我们也能感受到代码架构上的清晰化。
hw2
第二次作业的bug主要是因为一处遗漏而导致的meg恶行bug,在强测多个点都出现了这个bug,在bug修复中修好后就大部分通过了。
另外一小部分是在优化中出了问题,这告诉我们优化需谨慎!!!
下面是hw2的一些指标
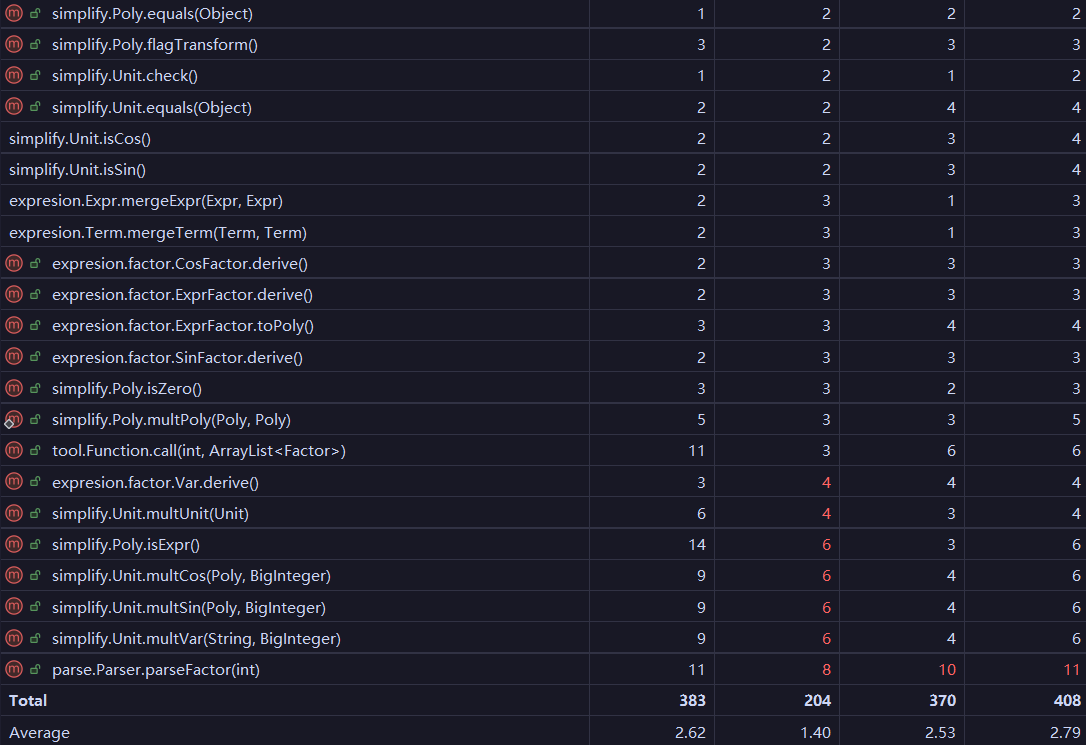
hw3
第三次作业的bug是因为一处笔误导致的bug,这里就不展开描述了。
指标展现的优点
首先我的代码的耦合程度相较于我身边的同学是比较低的,我将各个任务分散到不同的模块中,从string到Expr的转换,处理FuncFactor,处理DerFactor,构建多项式并输出都是由独立的模块负责,并且将来如果有新的因子和处理,我还可以通过增添新的模块来完成这个任务,我的代码也因此可读性很高,也十分方便定位bug。
指标展现的缺点
但是由于上面不断的增添模块,如果需求越来越多,我的代码量也会越来越多,这将变得不利于维护。
优化
本单元的优化我做的比较简单,主要集中在三角函数的合并优化。
首先是合并同类项,我重写了Expr、Term和Factor的HashCode和equals方法,这使得我判断两个Unit是否是同样的变得很简单,只需要调用containsKey()判断是否已经在Poly里即可。
但是这样还有一个问题,就是如果sin或者cos内的factor正好相差一个-1的系数呢?这个问题要完全解决比较苦难,所以我选择根据sin或cos里Poly的第一个Unit的符号做判断,如果是负号,那我选择将负号提到外面,这样一来即没有增添很多的代码,又能大大提高同类项的识别与合并概率。
发现别人程序bug所采用的策略
在经历hw2的惨痛教训后(没有好好评测自己的代码),我决定自己搭建一台评测机(主要是请教ChatGpt老师和DeepSeek老师)我让生成式人工智能为我写了一份评测数据的生成脚本,然后交给我自己写的自动化对拍程序,将互测小组内的成员的代码去跑我生成的评测数据并进行对拍,将不一致的结果记录下来,然后为了避免是同质的Bug,选择帮他们修复并重新评测。
这就是我这次hack采取的策略,但是不足的是,生成评测数据的脚本不是很强,并没有为我测处太多的bug,但好在为我自己的强测带来了很多好处。
心得体会
- 写代码前先思考 : 如果啥都没想好就开写代码,那么这段代码一定会重构。
- 多看学长学姐博客 : 学习前人经验和优秀的架构是一种好习惯,有时还能启发自己的新思路。
- 注意代码的可读性和可拓展性 :千万不要为了代码量和编写方便而放弃代码的可读性,同时,这次Unit1的迭代开发经验还启示我一定要注意可拓展性。
- 写代码时多关注代码指标 : 如果你发现自己的耦合度或者什么其他指标超标时,那么你就需要改一改你的架构了。